なぜ自分がロボットでないことを示す「CAPTCHA」はどんどん難しくなっているのか?
インターネットでサービスの登録や利用を行う際、ロボットでないことを証明するために「CAPTCHA」というテストを要求されることがあります。「CAPTCHA」は登場初期からだんだんと難易度が上がっていることが知られており、もはや人間であってもクリアに失敗することがありますが、「一体なぜ『CAPTCHA』は次第に難しくなっているのか?」という疑問について、ニュースメディア・VoxのYouTubeチャンネルが解説しています。
Why captchas are getting harder - YouTube
コンピューターは常に「このユーザーはロボットなのではないか?」と疑っており……

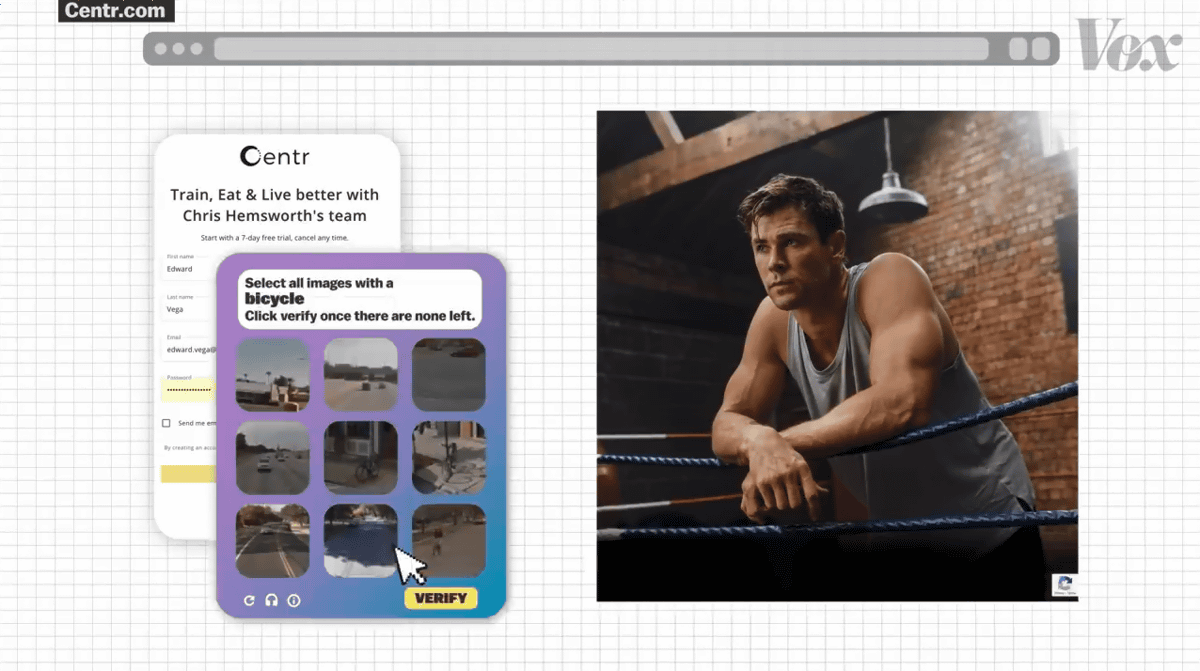
フィットネスクラブに登録する時などにCAPTCHAを要求してきます。
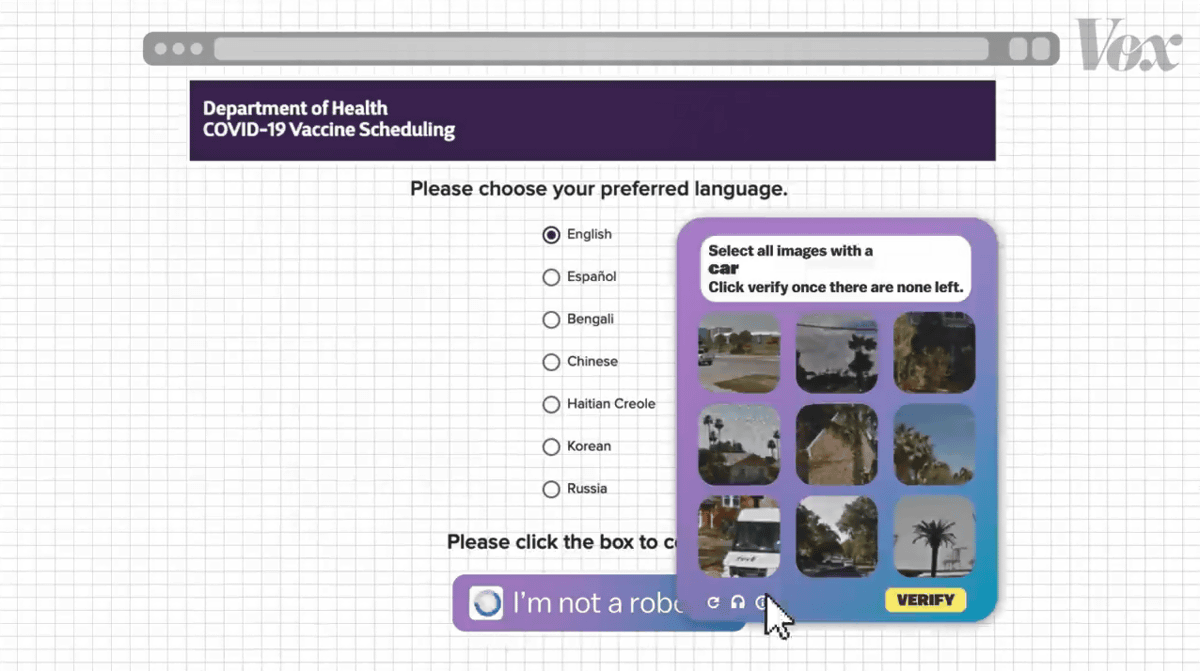
ワクチンの接種予約や……
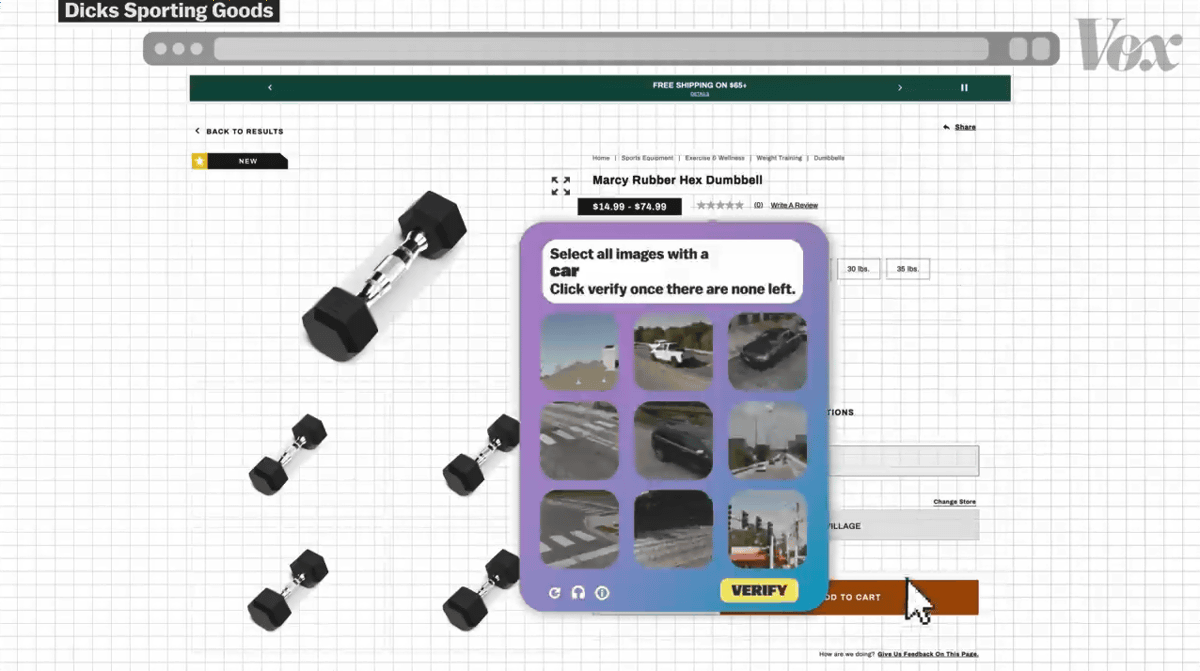
ダンベルを買うときにもCAPTCHA。
至るところでCAPTCHAを要求されてうんざりした人も多いはず。

さらに人間なのにCAPTCHAによく引っかかってしまうというのもうんざりした気持ちを倍加させます。

近年では次第にCAPTCHAが難しくなっているといわれており、Voxはその舞台裏について「CAPTCHAの第一人者」に取材を行いました。

「CAPTCHAは『Completely Automated Public Turing test to tell Computers and Humans Apart(コンピュータと人間を区別する完全に自動化された公開チューリングテスト)』の略称です」と説明するのは……

CAPTCHAの初期開発者でありカーネギーメロン大学の准教授を務めるルイス・フォン・アン氏。

アン氏がCAPTCHAに取り組もうと思ったのは、自身がカーネギーメロン大学の博士課程時にYahoo!の主任研究員が行った講演に参加したことがきっかけ。講演の中で主任研究員は、「悪意を持った人々がスパムメール送信のために数百万ものメールアドレスを取得するプログラムを作成しているが、それを防ぐことが難しい」というYahoo!が抱える課題について語ったとのこと。
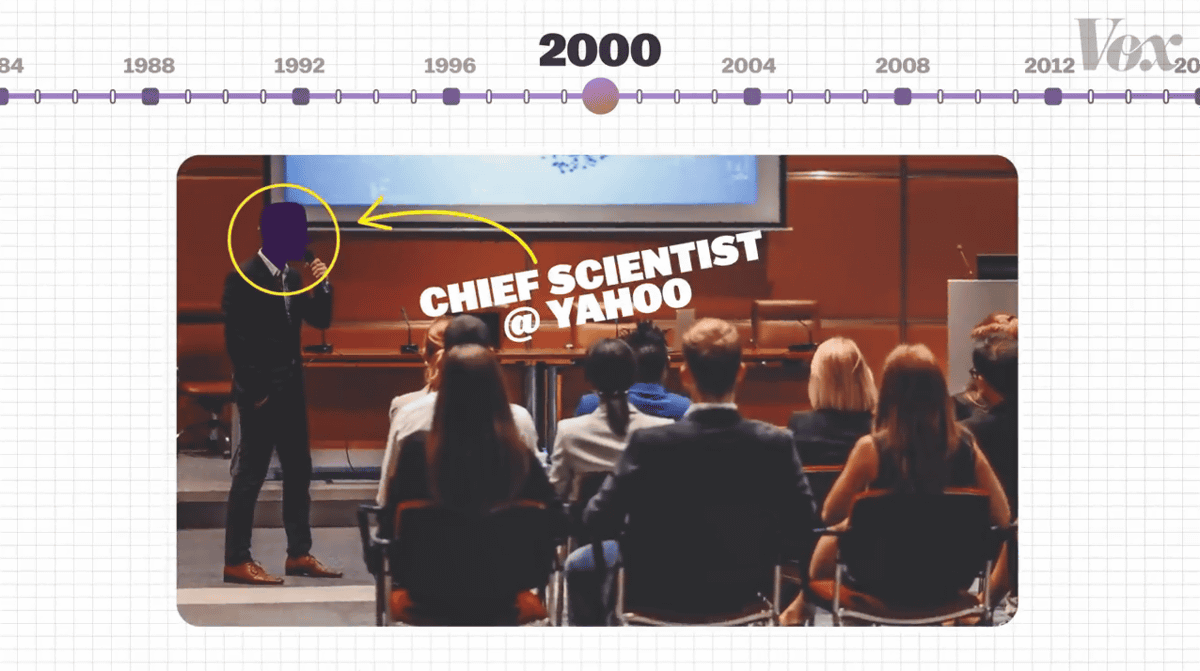
この問題を聞いたアン氏は、「人間とコンピューターを区別するテストが必要だ」と考えました。

「人間とコンピューターを区別するテスト」は年齢・性別・教育・言語に関係なく全ての人間がパスできる必要がありますが、コンピューターはパスできない仕組みにする必要があります。しかし、このテスト自体はコンピューターによって運用されるため、運用のためのコンピューターは「コンピューターにはパスできないテスト」を評価できなくてはなりません。

「これは一種の逆説的なアイデアです」とアン氏は述べています。

やがてアン氏らの研究チームは、「人間は光学文字認識、つまり文字を読むことが非常に上手だ」という発想にたどりつきました。

人間はさまざまな照明条件や角度であっても文字を読むことができ……

印刷された文字とはかなり形が異なる手書きの文字でも認識できます。

多くの人は子どもの頃から文字を読む訓練を積み重ねているため、非常に優れた文字認識能力を有しているとのこと。

「これには頭の良さやつづり方の理解は必要はありません。これは一種のパターンマッチングです」とアン氏はコメント。当時のコンピューターは文字を識別する能力が低かったため、ゆがんだ文字を読ませるテストは非常に高い精度で人間とコンピューターを識別できました。

また、プログラマーはテストを運用するコンピューターに正答を教え込むことが可能です。一方、答えを知らないコンピューターは形をゆがめられた文字を識別することはできませんでした。
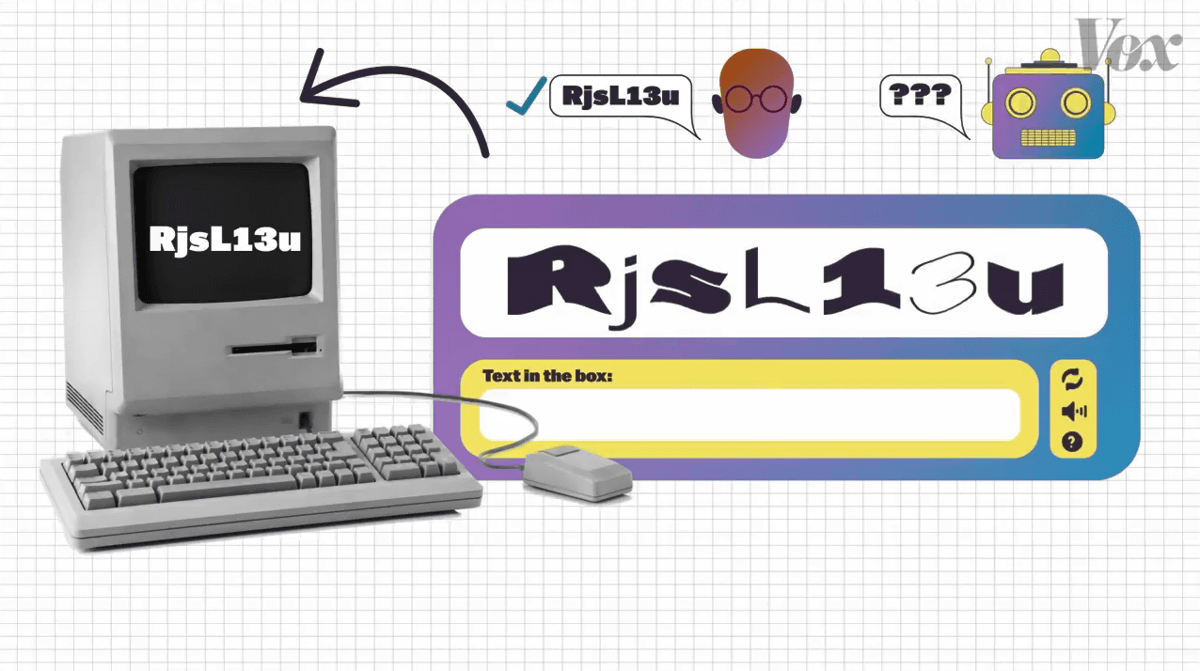
こうして、アン氏らが開発したCAPTCHAのコードはYahoo!に渡され、Yahoo!はすぐに登録ページでCAPTCHAを使い始めました。

CAPTCHAは実装後わずか数週間で、1日数百万回も使われるようになったとのこと。

実際にCAPTCHAはよく機能し、人間とコンピューターを識別していました。

一方、コンピューターも人間の回答を分析し、次第に文字を識別する能力を向上させていったそうです。
その後、2005年に登場した「reCAPTCHA」は、2つの単語からなる認証方法を採用しています。最初の単語は従来のCAPTCHAと同様にコンピューターが生成した文字でしたが……
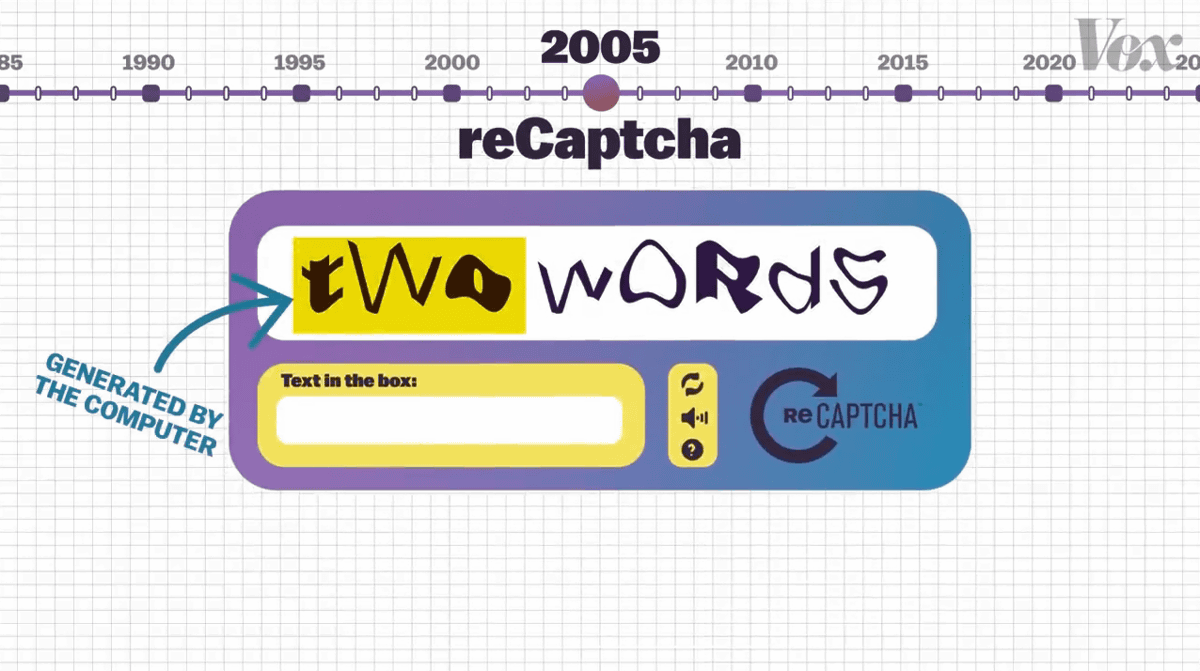
2つ目の単語は古いニューヨーク・タイムズの電子アーカイブから抽出されたものであり、コンピューター自体も答えを知りませんでした。

reCAPTCHAでは、1つ目の単語が正しい場合は2つ目の単語も正しいものと見なし……

複数人のテスト結果を照合して2つ目の単語の正しい答えを分析します。
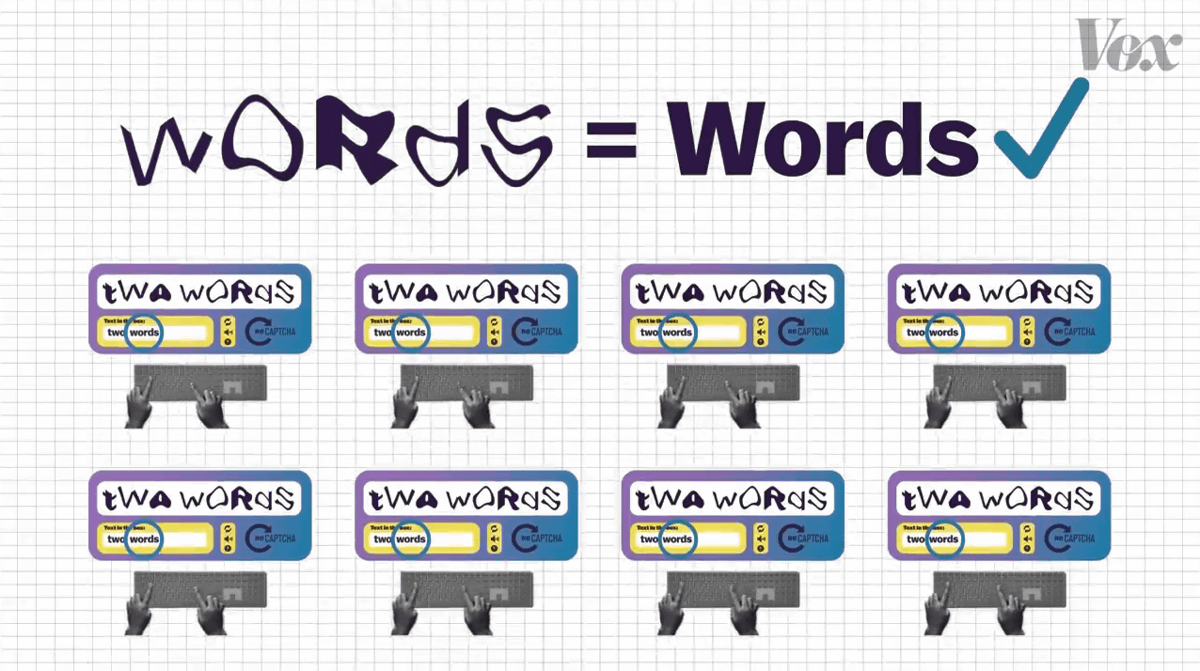
このシステムを使うことで、これまで文字としてデジタル化されていなかったニューヨーク・タイムズの記事をデジタル化することが可能となりました。世界中の人々がreCAPTHCAを使うことで、1年分のニューヨーク・タイムズがわずか1日でアーカイブ化されたとのこと。

Googleは2009年にreCAPTCHAを買収し、スキャンした本や新聞のアーカイブを作成するためにreCAPTCHAを使い始めました。

一方でreCAPTCHAが何回も繰り返し使われたことで、「コンピューターが識別しにくいゆがんだ文字のデータセット」も構築されてしまい、このデータセットを使用してコンピューターが学習できるようになりました。
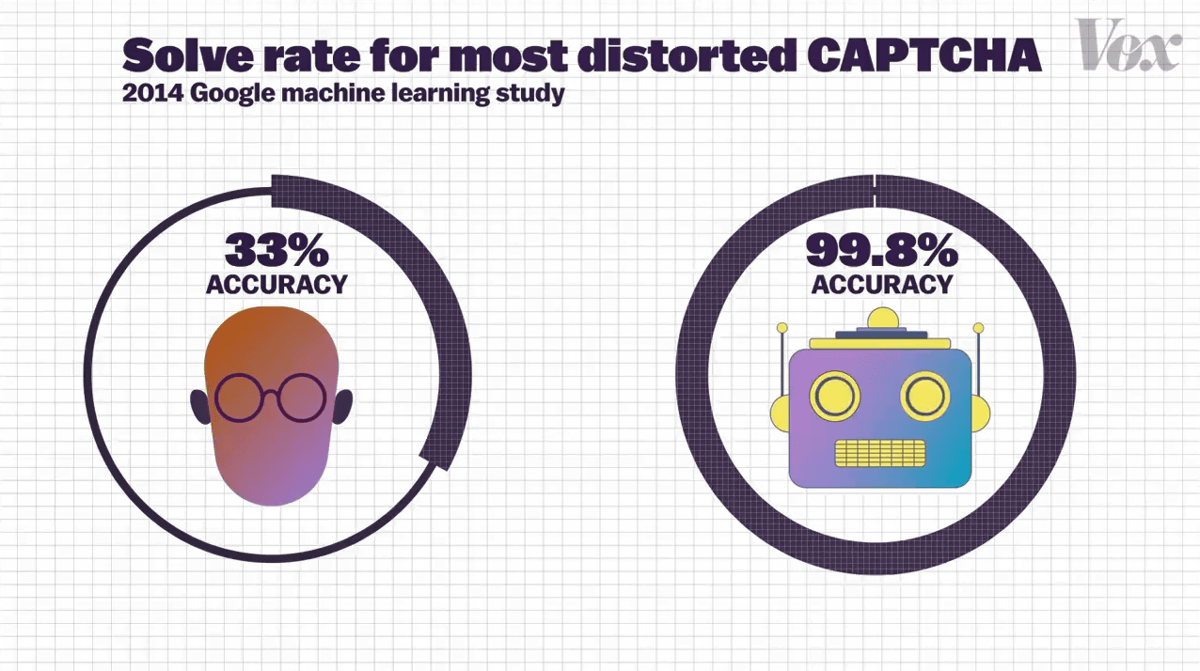
2014年にGoogleが行ったテストでは、人間が最もゆがんだ文字を読み取る精度は33%でしたが、コンピューターでは99.8%となり、コンピューターが人間を上回る精度で文字を識別できることが示されました。
そしてGoogleは2014年に、「reCAPTCHA v2」という新たなCAPTCHAのバージョンを発表しました。reCAPTCHA v2はテキストの代わりに画像を使用する方法であり……

GoogleはreCAPTCHA v2を介して人間に現実世界の物体を識別させ、得られたデータセットでコンピューターを訓練しました。

reCAPTCHA v2で消火栓や信号機、横断歩道などを識別するように求められることが多いのは、Googleがこのデータを自動運転車の開発に用いたり、Googleマップの改善に利用しているからです。

しかし、やはりコンピューターは新たな識別方法もクリアするようになっており、新たなテストの導入が求められることとなりました。

そして開発されたのが、テストを用いずにユーザーの行動から人間かどうかを識別する「reCAPTHCA v3」です。

reCAPTHCA v3はユーザーにテストを出すことなく、バックグラウンドでユーザーの行動を追跡するため、ユーザーは自分が「人間なのかロボットなのか」を判別されていることすら気付きません。
もしテキストを読む時間やクリックの速度から「このユーザーはロボットの可能性が高い」と判断した場合、reCAPTHCA v3は標準的な画像識別テストを出すか、2要素認証を要求するとのこと。

「あなたがウェブを使うなら、基本的にあなたは追跡されています」とアン氏は述べ、行動が知らないうちに監視されているのは気味が悪いかもしれないものの、いちいちパズルを解くよりはるかに優れていると主張しています。

しかし、reCAPTHCA v3すらも絶対の解決策とは言えず、アン氏は個人的な信念として「いずれコンピューターは人間ができることを全て実行可能になる」と考えているとコメント。従って、いつかは人間とロボットを識別できなくなる可能性があるとのことです。



・関連記事
Cloudflareが「CAPTCHAの狂気」からの完全脱却を表明、物理セキュリティキーを使うシステムを提案 - GIGAZINE
CAPTCHAは回答者が「人間」であると証明するのではなく「アメリカ人である」ことを証明するだけとの指摘 - GIGAZINE
GoogleのreCAPTCHAに対抗する「hCaptcha」の市場シェアが15%を突破 - GIGAZINE
「CAPTCHA」を要求することで自動検出を回避するマルウェア攻撃が登場 - GIGAZINE
文字の読解や画像クイズをやらされる「CAPTCHA」はボットの進化と共に難度が上がっていく運命 - GIGAZINE
・関連コンテンツ